I do the same. I can SSH into my router at home (which is on 24/7), then issue a WOL request to my dev machine to turn it on.
You don't even have to fully shut down you dev machine, you can allow it to go into stand-by. For that it needs to be wired by cable to LAN, and configured to leave the NIC powered on on stand-by. You can then wake up the device remotely via a WOL magic packet. Maybe this is possible with WLAN too, but I have never tried.
Also, you don't need a Tailscale or other VPN account. You can just use SSH + tunneling, or enable a VPN on your router (and usually enjoy hardware acceleration too!). I happen to have a static IP at home, but you can use a dynamic DNS client on your router to achieve the same effect.
I used to work as a freelancer back in the days. I worked a lot for a customer became a good friend. At first I'd work on his projects, but this ultimately shifted to a model where I'd work on projects for his clients, I would bill him, and he would add his margin and bill the end-customer. It worked out great this way.
One day I got a call from him saying that our 'mutual' customer had an urgency job. They were supposed to do a national roll-out of a new payment system, but seemed to have forgotten about a bunch of legacy PoS systems that were still operational and couldn't easily be replaced. Because I was seemingly the only one that was still familiar with this particular system (I worked on it once in the past), the end-customer approached my friend whether I would be available to do this quick. This was in late November, and the rollout was planned for Januari. Because this end-customer is a government org, I realised we'd be guaranteed they wouldn't be working during the holidays (which, in my country is typically 2 weeks for Christmas and new-year's), so really we had only 10 days or so to get it done in time for their team to test it before they holiday shutdown.
I didn't feel like doing such a complex job on such tight deadline. So, I quoted a much higher rate than normal. I also quoted for a multitude of hours that I thought was required, due to the typical overhead that this large end-customer would surely incur. Finally I also added a retainer fee, because I knew that if problems would occur (likely on the last day before the rollout), I'd have to drop anything I was doing and work for them.
I got the job.
I worked feverishly to meet the deadline. I cancelled commitments on other projects, paid an extortionate amount for testing hardware and overnight delivered to my office, bought very expensive testing gear, signed all the NDA's required to work on PoS card payment interfaces, etc. I then worked basically round the clock for 10 days straight to get it done. I did get it done in time, submitted the code to the repository and fired an email to the team-manager that it was in fact done a day early. ...I was greeted with an auto-reply the manager would be on holiday till mid-January, which was the week that entire new payment system had to be rolled out nation-wide.
I wasn't feeling great about it, but my friend urged me to send the invoice for the work I had done, and also the retainer for the rest of December and January. This would allow the customer to write of the expenses in the current calendar-year. I sent the invoice, it was the most amount of money I'd ever invoiced, and I'd normally invoiced per month, this was for a mere 10 days.
December passed, no response from the supposed review team. I stayed on stand-by, declined any other work, stayed sober during the various new-year's office parties, always brought my laptop along, etc.
January came and went. Still no response from the code review team. The new payment system was due to be rolled out mid-january, but nothing had happened. The company had done extensive ad-campaigns beforehand announcing the new payment convenience for their end-users, so the only 'feedback' I saw were frustrated users on Twitter. I still felt bad about charging for the retainer.
This kept going. At some point I did stop sending invoices for the retainer. My friend always paid me in advance (the end-customer was notoriously slow to pay, though did always pay in the end), and I didn't want to cause him too much exposure.
To my knowledge, the software I wrote was never used in the end. To the public it was stated that the PoS systems were simply too old to be upgraded (not true, obv) and that they'd replace them 'soon'. It is now 4 or 5 years laters, the old PoS terminals are still there, sans the functionality I added.
By pure coincidence, years after the job I found out that an old friend of mine, who was also a freelancer at the time, was tasked around that same time by the same customer to do a code-review of a supposed PoS system upgrade. Without realising, he reviewed my code! He was under the same time pressure, and did the code review during Christmas to deliver the results on time before the national rollout in mid-January. He also charged a huge amount of money for it, was also paid, and also never heard about it again. At least he said he remembered being impressed by the quality of the code, and didn't find any defects. So that's about the best outcome of the project I guess.
My takeaway from this: If you are a freelancer, and a large customer wants something done in a hurry, charge more than you ever dared, don't feel bad about it. You'll find that suddenly there isn't as much of a deadline anymore. If the customer declines due to the price, you should be happy for dodging a bullet.
I bought the top of the line TV from Samsung in 2011. The 'smart' functionality services went offline after a year or two, which means all 'smart' functions no longer work and I am now happily using it as a dumb TV.
Eventually every smart TV becomes dumb when they inevitably shut down the backend services.
> Eventually every smart TV becomes dumb when they inevitably shut down the backend services.
Except that on newer tvs all the nagging will still be there, all the ads will be "frozen" in time (mine has ads for stuff from 2023, the last time I connected it for some firmware update that _GASPS_ actually fixed some things) and some features may depend on internet connectivity. The manufacturer may care to release a final update and solve these issues, but you know they are much more likely to fraudulently just disable features that worked offline as a last middle finger.
Repeat with me, SaaS is fraud. Proprietary digital platforms are fraud.
I've had a very similar problem with my cable internet circa 2010. It must have been DOCSIS 3.0. Multiple times a day my connection would stop working completely. The modem's 'connected' and 'carrier up' and 'carrier down' lights were on, and I had LAN communication with the modem, but no data would pass though on the WAN side.
From the management page of the modem (I later learned you weren't supposed to know about) I could see the upstream and downstream carriers were correctly established and still operational, but on the IP (PPPoE) level the TX (upstream) packet counter was increasing, but the RX (downstream) packet counter did not. Releasing the IP on my router (remember, it was PPPoE), then waiting 10 minutes or so before renewing the IP via DHCP would bring connectivity back.
I would call to my ISP (the largest ISP in my country) to try to resolve the issue. Every. Single. Time. I had to explain to the support employee that yes, I did disconnect and reconnect power, yes, my computer's software was up to date, yes, I did try connecting via LAN directly to the modem to eliminate any possible router issues, etc.
Now, at this point in the story I should point out that I held a degree in electrical engineering, specialising in embedded systems and high-speed data transmission and also had just about all Cisco networking certifications. I was more than qualified to design cable modems myself, imagine the frustration wasn't able to fix this issue.
One night I came home to the same problem, called customer service again, fully prepared to do the 'dance' of answering every basic troubleshooting question. But to my surprise, the guy on the phone seemed legit knowledgable. When I described him the symptoms I saw from the modem's management page he was rather surprised that I managed to discover that functionality, but said he knew what the problem would be then.
The support employee was quickly to confirm that someone in my neighbourhood hard-coded his IP-address instead of allowing DHCP (a common trick back in the day to get a static IP on a residential cable connection), and that that IP was clashing with the IP their DHCP would assign to my router's MAC address. He asked me what brand of router I had, and had to explain to him that it was a self-built OpenBSD box. His response was: "great! then you probably know how to spoof the MAC on your WAN interface then?". I did, I changed my MAC to a value he gave me, and immediately my connection came back up. He explained me that any MAC address starting with AB:BA (named after the band) was reserved for a special block of customers with this kind of issue.
We continued chatting a bit about DOCSIS, networking technology, modulation types, OpenBSD (it was also his favourite OS) and much more nerdy stuff. At some point I asked him, respectfully, how someone with his knowledge ended up at the support helpdesk of an ISP. He then told me he was the ISP's CTO, in charge of all network operations, and that he was just manning the helpdesk while his colleagues were on a diner break...
Man, I remember when you told this story some years ago, and I still very much like it !
(I have an hnrss.org feed with all comments mentioning OpenBSD, so, I was bound to catch it).
What a jump, I'd be curious to hear first why anyone would prefer Intel above pretty much anything else, but also secondly how the actual experience difference between the two after working at both, must be a very strong contrast between them.
On her website it says she is working on GPU drivers there - I wouldn't be surprised if that's something she greatly enjoys and Intel gave her then opportunity to work on official, production shipping drivers instead of reverse engineered third party drivers.
Maybe she was given a huge signing bonus to avoid her working on making X86 irrelevant? Combined with perhaps some interesting project to work on for real.
I wouldn't have thought so 5-10 years ago, but with Microsoft offering Windows on ARM the is really no OS that specifically targets x86 (Legacy MS products will keep it alive if the emulation isn't perfect).
The thing is, x86 dominance on servers,etc has been tied to what developers use as work machines, if everyone is on ARM machines they'll probably be more inclined to use that on servers as well.
Microsoft has tried Windows on ARM, like, 5 times in the past 15 years and it's failed every time. They tried again recently with Qualcomm, but Qualcomm barely supports their own chips, so, predictably, it failed.
The main reason x86 still has relevance and will continue to do so is because x86 manufacturers actually care about the platform and their chips. x86 is somewhat open and standardized. ARM is the wild, wild west - each manufacturer makes bespoke motherboards, and sockets, and firmware. Many manufacturers, like Qualcomm, abandon their products remarkably quickly.
Huh? Qualcomm announced the X2 chips just 2 months ago with shipments for early next year. Looked at a local dealer site and there's MS, Dell, Asus and Lenovo WinArm machines (with current gen Elite X chips).
Yes, Windows on desktop hardware will probably continue mainly with x86 for a while more, but how many people outside of games, workstation-scenarios and secure scenarios still use desktops compared to laptops (where SoC's are fine for most part)?
1: It's not meant to be cute but rather incredulity at a statement of declaring something to having failed that still very much seems to be in progress of being rolled out (and thus indicating that it'd be nice to have some more information if you know something the rest of the world doesn't).
2: Again, how are they failures? Yes, sales have been so-so but if you go onto Microsofts site you mostly get Surface devices with Snapdragon chips and most reports seems to be from about a year ago (would be interesting to see numbers from this year though).
3: Yes, I got a new x86 machine myself a month back that has quite nice battery life. Intel not being stuck as far behind on process seems to have helped a fair bit (the X elite's doesn't seem entirely power efficient compared to Apple however).
4: Yes, _I_ got an x86 machine since I knew that I'd probably be installing quirky enterprise dependencies from the early 00s (possibly even 90s) that a client requires.
However, I was actually considering something other than wintel, mainly an Apple laptop. If I'm considering options and being mostly held back by enterprise customers with old software I'd need to maintain the moat is quite weak.
My older kids previous school used ARM Chromebooks (currently x86 HP laptops at current upper highschool but they run things like AutoCAD), the younger one has used iPad's for most of their junior high.
Games could be one moat, but is that more due to the CPU or the GPU's being more behind Nvidia and AMD. Someone was running Cyberpunk 2077 on DGX Spark at 175 fps (x86-64 binary being emulated.. )!
But beside games and enterprise...
So many people that are using their computers for web interfaces, spreadsheets, writing, graphics(photoshop has ARM support) and so on won't notice much different about ARM machines (why my kids mostly used non-x86 so far), it's true that such people are using PC's less overall (phones and/or tables being enough for most of their computing), but tell a salesman Excel jockey that he can get 10-20% more battery life and he might just take it.
Now, if Qualcomm exits the market by failing to introduce another yearly/bi-yearly update then I'll be inclined to agree that Win-Arm has failed again.. but so far it's not really in sight.
I imagine there's also some challenging work that would be fun to dig into. Being the person who can clean up Intel's problems would be quite a reputation to have.
There’s a real limit on what level of problem one engineer can fix, regardless of how strong they are. Carmack at Meta is an example of this, but there are many. Woz couldn’t fix Apple’s issues, etc.
A company sufficiently scaled can largely only be fixed by the CEO, and often not even then.
I'm sure most would stay at valve if they could. The just do so much contract work, and I'm sure a stable job at intel is better pay, benefits and stability.
Would it shock you to hear that famous engineers with their own personal brand power have different opportunities and motivations than many/most engineers?
Their point is even made stronger by your comment. Engineers of this type don't experience megacorps like regular engineers. They usually have a non-standard setup and more leeway and less bureaucracy overhead. Which means brand isn't the biggest thing, the specific projects and end user impact are.
For what I remember, most of the DNS root servers used to run Bind9 exclusively. I'm glad to see that this is now more diverse with NSD and Knot also being used (see table 4 in the report).
Nothing against Bind9, but it is almost exclusively maintained by the ISC, so the DNS's future used to depend heavily on the ISC getting the funding needed to continue operating.
Not to mention how much better it is for standards/protocols/standarization to have multiple implementations of the same protocol in real-world usage so we can nail down the protocol in all situations. Bind9 almost ended up being "DNS" itself, which would have been bad overall, and instead we're seeing more diversity which means we'll be able to make better use of the specifications.
That hasn't been true for at least 15 years. I was a k-root DNS operator then, and we ran several software stacks on each cluster in case one had a bug.
I don't understand your sentiment against Cloudflare here.
Cloudflare also delivers a rather large portion of said public infrastructure free of charge. They also released a few of their own projects as FOSS, and regularly contribute.
Granted, the centralisation part worries me too, but it feels like a bit of a cheap shot against CF just because they are a large player.
My Lenovo X1E regularly burns 20% of its CPU cycles on some high frequency recurring interrupt. I did get pretty far with debugging it, but eventually gave up since I can't justify spending so much time on fixing a 'professional' laptop that I paid top dollar for.
It also has a multi-GPU setup that has never worked reliably under Linux, which is ironic as I opted for Lenovo due to its supposedly good Linux compatibility.
Switching between GPU modes is a hit or mis, waking up from stand-by often results in a blank screen, screen flickering, sporadic high fan speeds, etc. And then there's the coil whine, which seems to be fixed in some BIOS versions, then returns in the next. Supposedly it has something to do with power-saving measures.
Since I owned it there have been at least 20 BIOS version releases for 'improved performance and security', but none seem to actually fix anything. It's such a mess.
If you are running Linux, you can suspend using the following command, to re-initialize the GPU when resuming, which works around some ACPI bugs:
pm-suspend --quirk-vbe-post
I have a 1st-gen Lenovo X1 Yoga, and it is the only laptop series that has everything I want: an OLED display, a stylus, and a TrackPoint input. ACPI worked fine when I first bought it, and I can't remember if it's had one BIOS update or two, but after the most recent update, it sometimes won't wake from sleep. When that happens, he power LED fades on and off, no matter how many times I press the power button or close and open the lid. I have to hold the power button to force it off, then power it back on from a fresh boot.
Also, the Linux kernel added support for adjusting the OLED's brightness through ACPI, years ago, but it's never been supported on my laptop, and I have to resort to using xrandr to output dimmer images, which reduces bit depth.
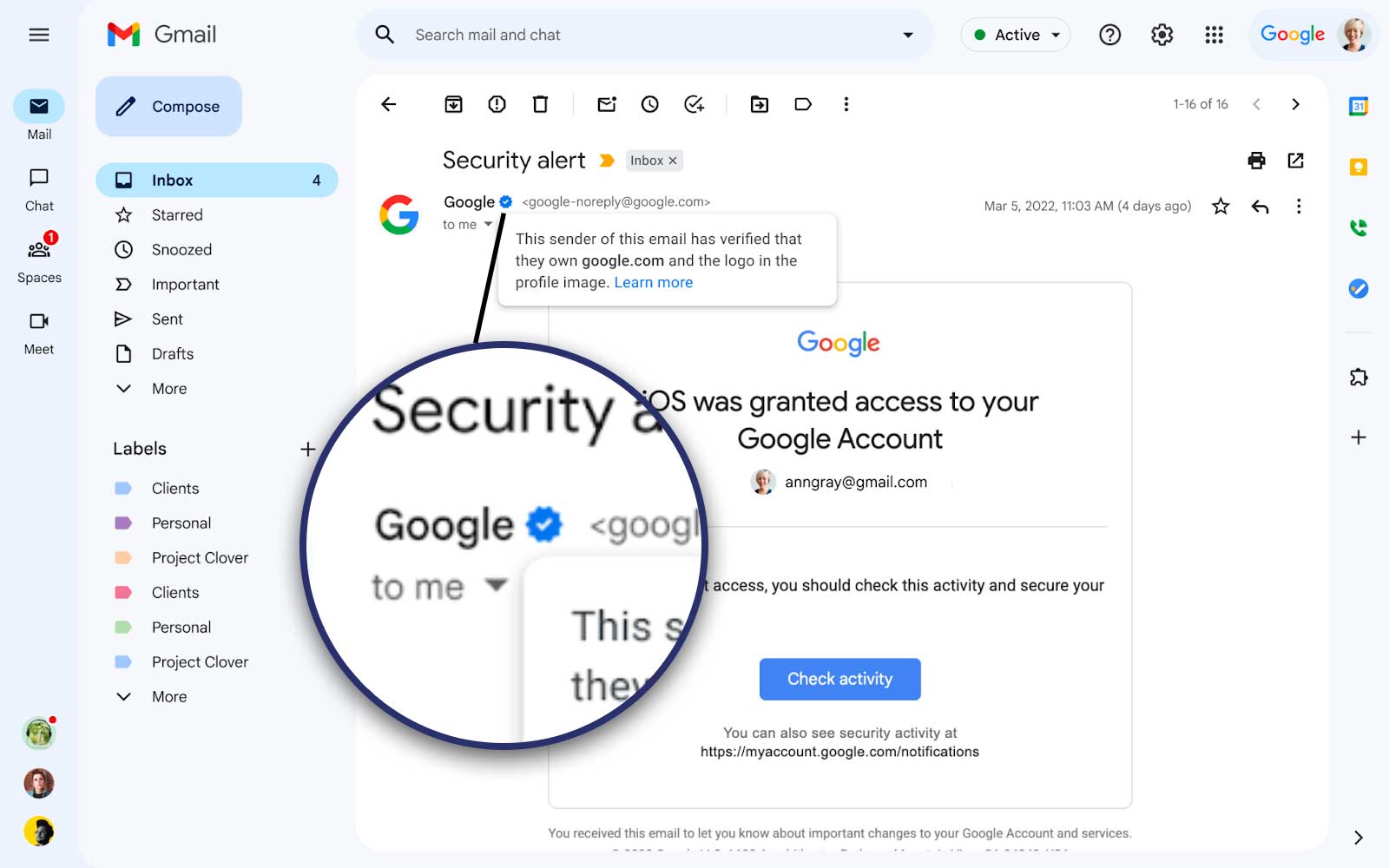
My best guess is that this attack was purely social engineering, and that no email spoofing actually happened. I think that the email message in question is actually a legit email from Google.
I'm not familiar with the formal account takeover process at Google, but my best guess is that the attacker simply requested an account takeover via the official Google process, which triggered this email to be sent by Google legitimately. By reading back the code in that email, the attacker was able to claim the Google account as theirs, thus access the Gmail inbox to reset the Coinbase password and access the authenticator backups from the Google Drive.
I would be very curious to see the original message headers of the email though.
I don't think that email he posted from legal@google.com is legit.
Look at the first sentence of the first paragraph and the first sentence in the second paragraph. Two grammar errors which are a dead giveaway it's fraudulent.
> Thank you for your assistance and understanding during your recent support
call, regarding a ficticious request aimed at accessing your Google
account.
Comma doesn't belong there and "fictitious" is misspelled.
> To follow all guidelines of the internal review properly. Please keep a
secure note with the temporary password which your support representative
has provided to you.
Out of place period. Should be a comma.
Legit, canned emails like this (especially from legal@google.com) would be proofread much better than this. It's fake.
Yes, at least two emails. One was the spoofed email from legal@google.com (which sadly convinced me this was legit) and the other was a Google recovery code email.
The spoofed email was deleted by the attacker, but I have a copy because I forwarded the email to phishing@google.com (something ChatGPT told me to do). The attacker then deleted the original but when I got my account back an hour later, Google bounced back the email. So that is the copy I have and the headers are not super helpful.
This is why 2FA isn't all it's cracked up to be. Strong passwords kept in your head are less brittle than managing something you can lose. If you have a real support channel (like employer IT) to deal with loss it's workable. Online services with no support is just asking for trouble.
2FA can be all it's cracked up to be. A Yubikey you have to physically possess, and physically touch, to login to a site is completely immune to this.
Yes, you need to buy hardware, yes you need 1 or more backup yubikeys in a bank safe somewhere in case your primary one breaks, but it is actually safe.
Strong passwords in your head are bad because they're even more phish-able. Like, with FIDO2, my yubikey will not login to "fake-coinbase.com", the attacker cannot proxy the data they get from the yubikey. For 2FA TOTP codes and for passwords, a phishing page can just proxy through the stuff to the real coinbase and login (as happened in this attack).
Eh just use a password manager; I use 1Password, it sync's to all my devices, I keep backups of everything (export primarily in json), autofills the 2fa codes, etc.
I mean. I have a little book on my desk with password hints. "2nd grade best friends phone number", "birthday of first dog". It also has a grid of random numbers/letters on the front page, so I can write "first_crush_b4*5". You'd have to have physical access to the book, and know what the hint leads to. It's un-hackable. I mean aside from social, or physically breaking into my house.
downvote all you want, this is third time in a month that basically "opsec" failure would've been prevented by a password manager that binds to domains, or passkeys. Both of which people regularly kvetch about here.
Yes, SPF (the original design) is horribly broken and trivially bypassed. The most prominent design flaw is that the inbound SMTP service uses the SMTP (rfc5321) MailFrom address for SPF validation, which is not the same sender address shown to the recipient, they can only see the the message (rfc5321) 'From' header address. SPF originally didn't require the domains in the MailFrom and From addresses to match, so an attacker would simply use a domain they control in the MailFrom address, and the 'spoofed' domain in the From header.
That was in 10 years ago though. DMARC fixed this by adding the alignment requirement, meaning that the domains in the MailFrom and From address must match. By default the alignment policy is 'relaxed', meaning that the MailFrom and From domains can differ in subdomain, as long as they share the same organizational domain. Setting the SPF alignment to strict (aspf=s) like you mention in your post requires the domains to match exactly, with no subdomain differences allowed.
So, it doesn't matter that Google doesn't use strict SPF alignment in the DMARC policy, the fact that they have DMARC already adds the requirement to SPF validation that the domains must match.
Yes, google.com and gmail.com use the same IP ranges in the respective SPF policies, but Gmail will never allow you to send email addresses from a domain that you do not own. This is why domain validation is required when you set up Gmail with a custom domain.
The only scenario where your explanation would hold up, is if the attacker was able to gain control of the DNS of a subdomain of the google.com domain, and successfully validated it as a custom domain in Gmail, then send emails from that subdomain in rfc5321.MailFrom address and the google.com domain itself as the rfc5322.From domain.
{kind=link}
You don't even have to fully shut down you dev machine, you can allow it to go into stand-by. For that it needs to be wired by cable to LAN, and configured to leave the NIC powered on on stand-by. You can then wake up the device remotely via a WOL magic packet. Maybe this is possible with WLAN too, but I have never tried.
Also, you don't need a Tailscale or other VPN account. You can just use SSH + tunneling, or enable a VPN on your router (and usually enjoy hardware acceleration too!). I happen to have a static IP at home, but you can use a dynamic DNS client on your router to achieve the same effect.
reply