I guess I was really looking for concrete examples and examples prior to the invention of or not related to the use of electronic technology.
For your non-technological items in your list, I don't see how public school, rock and roll, and desegregation are or were remotely related to experiments being ran on children by society.
Public school -- new concept that caused massive changes to social behaviors and patterns of association. Nobody knew ahead of time what the results of this would be, so it was as much an experiment as letting kids access Instagram.
Rock & roll -- millions of people thought that letting children listen to this African American music would corrupt their children and prove ruinous to children. Some parents demanded controls on access to this music, much as some parents are doing with Instagram today.
Desegregation -- it's well worth an hour of reading if you haven't spent the time so far. Here I will just say that it was obviously a profound change in social patterns, changes to the US's legal caste system, and had to be enforced at gunpoint. Nobody knew how it would play out, like nobody really knows how using Instagram at age 15 will impact people in midlife. This led to (white) parental outcry over the prospective changes, as many (white) parents did not want to participate in this social experiment.
Big changes, no real control groups, unpredictable outcomes. Experiments in a very real sense.
Have you seen literally any chart covering just the past one to two hundred years, or even just the past 50-70 years that covers emissions, population, industrial scale, environmental destruction, weather patterns, etc.? They would answer your question.
There is no end to the concrete evidence of the negative effect of humans towards the climate.
Here's something simple. Deforestation is directly caused by humans. (Note that wildfires "deforest" but without human intervention, they grow back and thus reforest.). So then ask yourself, what is the role of forests and jungles within the environment and climate?
Look at this article: https://ourworldindata.org/deforestation. What began 10,000 years ago, 200 years ago, and 100 years ago? This couldn't possibly be major changes in human activity could it?
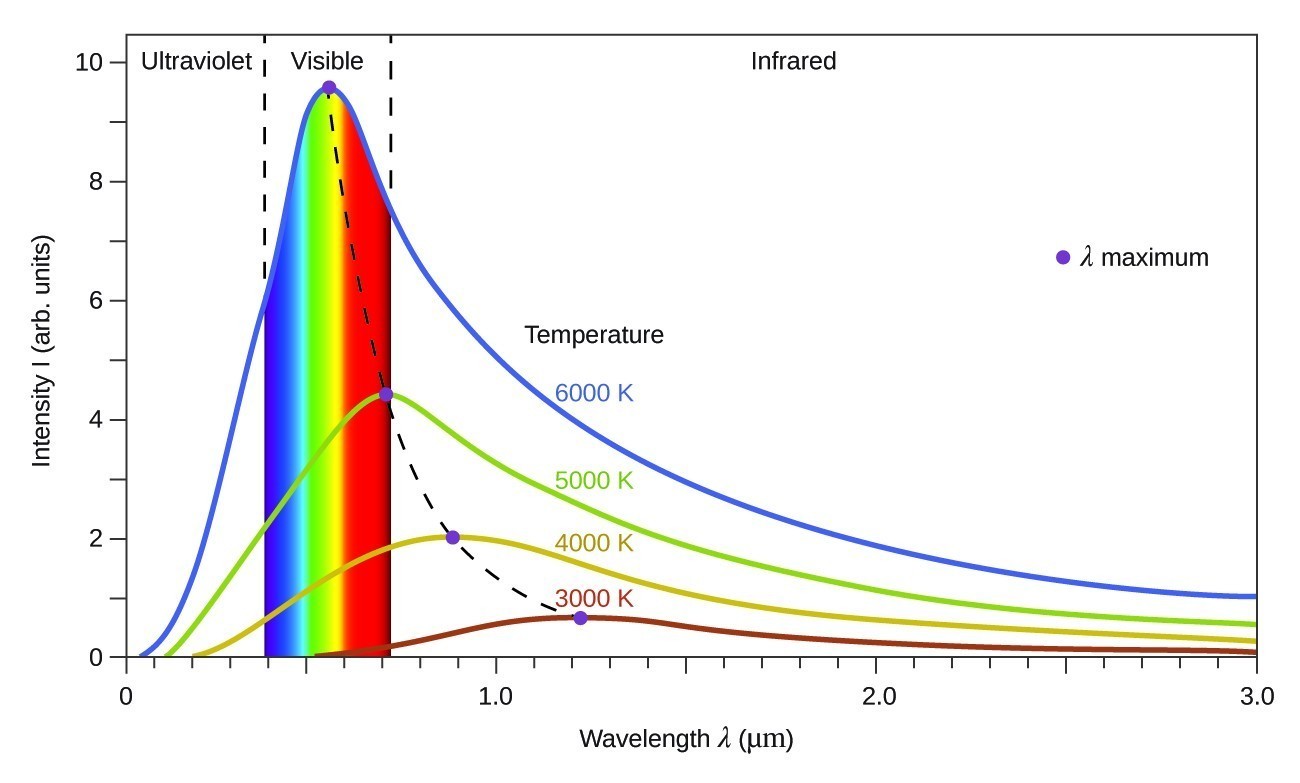
Green is the highest energy light emitted by our sun, from any part of the entire light spectrum, which is why green appears in the middle of the visible spectrum. The visible spectrum basically exists because we "grew up" with a sun that blasts that frequency range more than any other part of the light spectrum.
I have to wonder what our planet would look like if the spectrum shifts over time. Would plants also shift their reflected light? Would eyes subtly change across species? Of course, there would probably be larger issues at play around having a survivable environment … but still, fun to ponder.
That comment does not make sense. Do you mean the sun emits it's peak intensity at green (I don't believe that is true either, but at least it would make a physically sensical statement). To clarify why the statement does not make sense, the energy of light is directly proportional to its frequency so saying that green is the highest energy light the sun emits is saying the sun does not emit any light at frequency higher than green, i.e. no blue light no UV... That's obviously not true.
> Do you mean the sun emits it's peak intensity at green (I don't believe that is true either, but at least it would make a physically sensical statement).
Yes, that's what I meant, as I was sloppy with my language, and it's definitely true.
> Not quite, static typing is used at runtime, python type annotations are not
No, static typing is usually used AOT (most frequently at compile time), not usually at runtime (types may or may not exist at runtime; they don't in Haskell, for instance.)
Python type checking is also AOT, but (unlike where it is inextricably tied to compilation because types are not only checked but used for code generation) it is optional to actually do that step.
Python type annotations exist and are sometimes used at runtime, but not usually at that point for type checking in the usual sense.
> > Not quite, static typing is used at runtime, python type annotations are not
> No, static typing is usually used AOT (most frequently at compile time), not usually at runtime (types may or may not exist at runtime; they don't in Haskell, for instance.)
In fact, Haskell then allows you to add back in runtime types using Typeable!
My issue with them is that they claim their tools replace existing tools, but they don't bother to actually replicate all of the functionality. So if you want to use the full functionality of existing tools, you need to fall back on them instead of using Astral's "replacements". It's like one step forward and one step back. For me personally, speed of the tooling is not as important as what the tooling can check, which is very important for a language like Python that is very easy to get wrong.
If there are specific incompatibilities or rough edges you're running into, we're always interested in hearing about them. We try pretty hard to provide a pip compatibility layer[1], but Python packaging is non-trivial and has a lot of layers and caveats.
Is there any plan for a non-“compatibility layer” way to do anything manual or nontrivial? uv sync and uv run are sort of fine for developing a distribution/package, but they’re not exactly replacements for anything else one might want to do with the pip and venv commands.
As a very basic example I ran into last week, Python tooling, even the nice Astral tooling, seems to be almost completely lacking any good detection of what source changes need to trigger what rebuild steps. Unless I’ve missed something, if I make a change to a source tree that uv sync doesn’t notice, I’m stuck with uv pip install -e ., which is a wee bit disappointing and feels a bit gross. I suppose I could try to put something correct into cache-keys, but this is fundamentally wrong. The list of files in my source tree that need to trigger a refresh is something that my build system determines when it builds. Maybe there should be a way to either plumb that into uv’s cache or to tell uv that at least “uv sync” should run the designated command to (incrementally) rebuild my source tree?
(Not that I can blame uv for failing to magically exfiltrate metadata from the black box that is hatchling plus its plugins.)
> Is there any plan for a non-“compatibility layer” way to do anything manual or nontrivial?
It's really helpful to have examples for this, like the one you provide below (which I'll respond to!). I've been a maintainer and contributor to the PyPA standard tooling for years, and once uv "clicked" for me I didn't find myself having to leave the imperative layer (of uv add/sync/etc) at all.
> As a very basic example I ran into last week, Python tooling, even the nice Astral tooling, seems to be almost completely lacking any good detection of what source changes need to trigger what rebuild steps.
Could you say more about your setup here? By "rebuild steps" I'm inferring you mean an editable install (versus a sdist/bdist build) -- in general `uv sync` should work in that scenario, including for non-trivial things where e.g. an extension build has to be re-run. In other words, if you do `uv sync` instead of `uv pip install -e .`, that should generally work.
However, to take a step back from that: IMO the nicer way to use uv is to not run `uv sync` that much. Instead, you can generally use `uv run ...` to auto-sync and run your development tooling within an environment than includes your editable installation.
By way of example, here's what I would traditionally do:
python -m venv .env
source .env/bin/activate
python -m pip install -e .[dev] # editable install with the 'dev' extra
pytest ...
# re-run install if there are things a normal editable install can't transparently sync, like extension builds
Whereas with uv:
uv run --dev pytest ... # uses pytest from the 'dev' dependency group
That single command does everything pip and venv would normally do to prep an editable environment and run pytest. It also works across re-runs, since it'll run `uv sync` as needed under the hood.
My setup is a mixed C/C++/Python project. The C and C++ code builds independently of the Python code (using waf, but I think this barely matters -- the point is that the C/C++ build is triggered by a straightforward command and that it rebuilds correctly based on changed source code). The Python code depends on the C/C++ code via ctypes and cffi (which load a .so file produced by the C/C++ build), and there are no extension modules.
Python builds via [tool.hatch.build.targets.wheel.hooks.custom] in pyproject.toml and a hatch_build.py that invokes waf and force-includes the .so files into useful locations.
Use case 1: Development. I change something (C/C++ source, the waf configuration, etc) and then try to run Python code (via uv sync, uv run, or activating a venv with an editable install). Since there doesn't seem to be a way to have the build feed dependencies out to uv (this seems to be a deficiency in PEP 517/660), I either need to somehow statically generate cache-keys or resort to reinstall-package to get uv commands to notice when something changed. I can force the issue with uv pip install -e ., although apparently I can also force the issue with uv run/sync --reinstall-packages [distro name]. [0] So I guess uv pip is not actually needed here.
It would be very nice if there was an extension to PEP 660 that would allow the editable build to tell the front-end what its computed dependencies are.
Use case 2: Production
IMO uv sync and uv run have no place in production. I do not want my server to resolve dependencies or create environments at all, let alone by magic, when I am running a release of my software built for the purpose.
My code has, long before pyproject.toml or uv was a thing and even before virtual environments existed (!), had a script to build a production artifact. The resulting artifact makes its way to a server, and the code in it gets run. If I want to use dependencies as found by uv, or if I want to use entrypoints (a massive improvement over rolling my own way to actually invoke a Python program!), as far as I can tell I can either manually make and populate a venv using uv venv and uv pip or I can use UV_PROJECT_ENVIRONMENT with uv sync and abuse uv sync to imperatively create a venv.
Maybe some day uv will come up with a better way to produce production artifacts. (And maybe in the distant future, the libc world will come up with a decent way to make C/C++ virtual environments that don't rely on mount namespaces or chroot.)
[0] As far as I can tell, the accepted terminology is that the thing produced by a pyproject.toml is possibly a "project" or a "distribution" and that these are both very much distinct from a "package". I think it's a bit regrettable that uv's option here is spelled like it rebuilds a _package_ when the thing you feed it is not the name of a package and it does not rebuild a particular package. In uv's defense, PEP 517 itself seems rather confused as well.
uv needs to support creation of zipapps, like pdm does (what pex does standalone).
Various tickets asking for it, but they also want to bundle in the python interpreter itself, which is out of scope for a pyproject.toml manager: https://github.com/astral-sh/uv/issues/5802
Their integration with existing tools seems to be generally pretty good.
For example, uv-build is rather lacking in any sort of features (and its documentation barely exists AFAICT, which is a bit disappointing), but uv works just fine with hatchling, using configuration mechanisms that predate uv.
(I spent some time last week porting a project from an old, entirely unsupportable build system to uv + hatchling, and I came out of it every bit as unimpressed by the general state of Python packaging as ever, but I had no real complaints about uv. It would be nice if there was a build system that could go even slightly off the beaten path without writing custom hooks and mostly inferring how they’re supposed to work, though. I’m pretty sure that even the major LLMs only know how to write a Python package configuration because they’ve trained on random blog posts and some GitHub packages that mostly work — they’re certainly not figuring anything out directly from the documentation, nor could they.)
Getting from 95% compatible to 100% compatible may not only take a lot of time, but also result in worsening the performance. Sometimes it's good to drop some off the less frequently used features in order to make the tool better (or allow for making the tool better)
Damn it, this unicorn farting rainbows and craping gold is not yet capable of towing another car. I don't know why they advertise it as a replacement for my current mode of transportation.
The market has never solved anything in ways that are beneifical for humanity. (Just commenting on the first part of your comment, given that your last sentence implies you're just saying what market evangelists would say.)
Plus, mathematics isn't just a giant machine of deductive statements. And the proof checking systems are in their infant stages and require huge amounts of efforts even for simple things.
Theres nothing difficult about formalizing a proof you understand.
Formalizing hot garbage supposedly describing a proof can be arbitrarily difficult.
The problem is not a missing library. The number of definitions and lemmas indirectly used is often not that much. Most of the time wasted when formalizing is discovering time and time again that prior authors are wasting your time, sometimes with verifiably false assumptions, but the community keeps sending you around to another gap-filling approach.
> Theres nothing difficult about formalizing a proof you understand.
What are you basing that on? It's completely false.
If that were true, we would have machine proofs of basically everything we have published proofs for. Every published mathematical paper would be accompanied by with its machine-provable version.
But it's not, because the kind of proof suitable for academic publication can easily take multiple years to formalize to the degree it can be verified by computer.
Yes of course a large part depends on formalizing prior authors' work, but both are hard -- the prior stuff and your new stuff.
Your assertion that there's "nothing difficult" is contradicted by all the mathematicians I know.
Sure the history of mathematics used many alternative conceptions of "proof".
The problem is that such constructions were later found to be full of hidden assumptions. Like working in a plane vs on a spherical surface etc.
The advantage of systems like MetaMath are:
1. prover and verifier are essentially separate code bases, indeed the MM prover is essentially absent, its up to humans or other pieces of software to generate proofs. The database just contains explicit axioms, definitions, theorems claims, with proofs for each theorem. The verifier is a minimalistic routine with a minimum amount of lines of code (basically substitution maps, with strict conditions). The proof is a concrete object, a finite list of steps.
2. None of the axioms are hardcoded or optimized, like they tend to be in proof systems where proof search and verification are intermixed, forcing axioms upon the user.
C/C++ basically demand that codebases be large. And we hear all the time about software troubles written in these languages. Finding reports of this are almost endless.
I think people who write complex applications in more sane languages end up not having to write millions of lines of code that no one actually understands. The sane languages are more concise and don't require massive hurdles to try and bake in saftey into the codebase. Safety is baked into the language itself.
{kind=link}
reply