I did not see any point to listing out the cons as others have already done it a bunch of times. I was trying to focus on what moving to a monorepo solved for us (which was optics and poor ux).
> ‘personal data’ means any information relating to an identified or identifiable natural person (‘data subject’); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person;
This does not reference hashing, which can be an irreversible and destructive operation. As such, it can remove the “relating” part - i.e. you’ll no longer be able to use the information to relate it to an identifiable natural person.
In this context, if I define a hashing function that e.g. sums all ip address octets, what then?
The linked article talks about identification numbers that can be used to link a person. I am not a lawyer but the article specifically refers to one person.
By that logic, if the hash you generate cannot be linked to exactly one, specific person/request - you’re in the clear. I think ;)
Re: docs - oops. We were frantically putting stuff together and linking before the docs were in that location - the link is supposed to be https://docs.streamdal.com/en/core-components/sdk/ . Fixed it in the readme.
re: libs vs sdk - we named it that in anticipation of exactly having to do some funky stuff. As it stands, we are already doing grpc, Protobuf, wasm and having it all interop across all languages is not easy - so having to introduce some sort of a “helper” binding/lib is not at all unlikely.
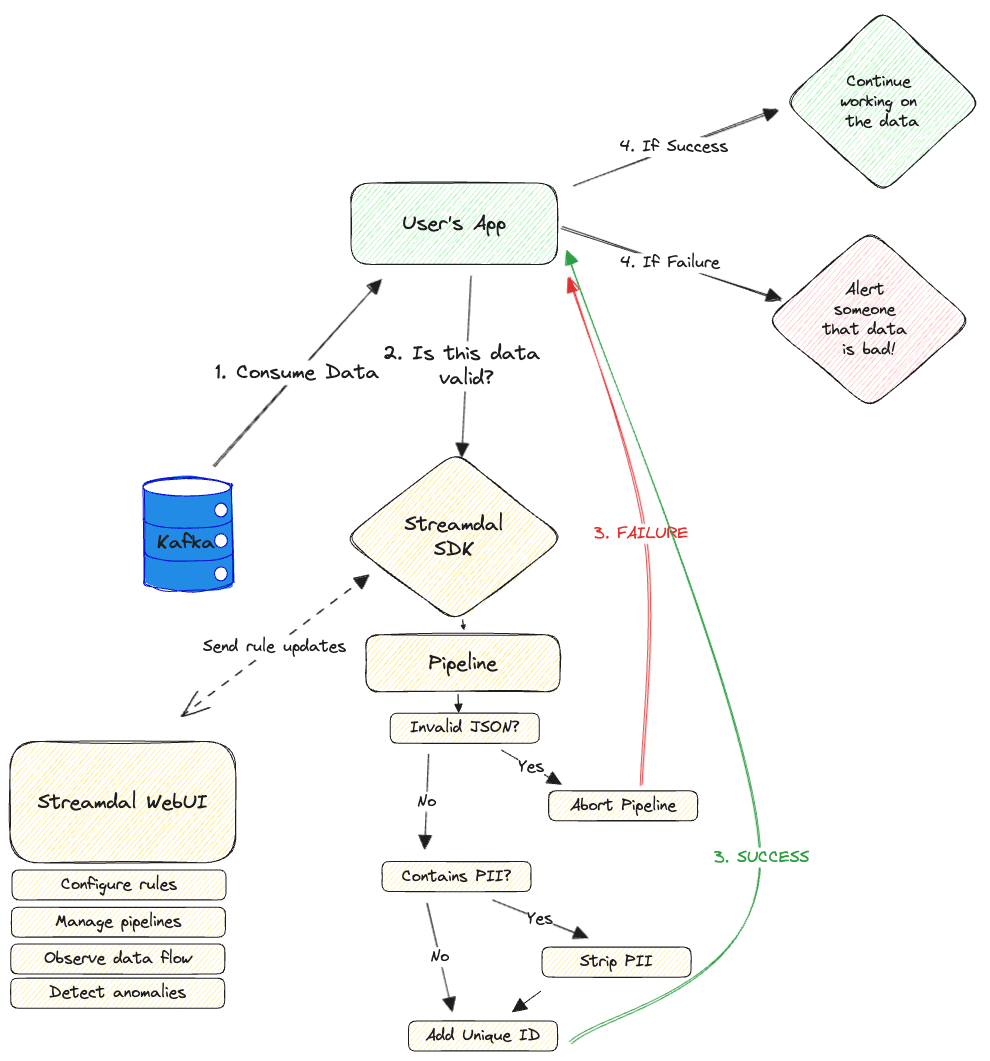
Besides that, the “tail” part is really a small part of the functionality - the overall idea is that the sdk/lib has access to most/all I/O of the app and is able to interact with the payload that the caller provides before it is sent on its way.
Traditional pipes aren’t really in the equation.
We went with calling it “tail” because it’s easier to explain instead of “it’s a lib that an app owner can wrap their i/o calls with to enable calling dynamic wasm”… and that’s still not the whole thing haha
Hmm good idea about the spark integration - integration is possible with basically anything that you’ve got code-level access to. I don’t know about messaging though - runtime data transformations for spark? I guess data folks would have no problem with that hmmm.
And re: emojis - we’ll tone it down - we were all working hard on docs late into the night and may have gotten a little wild with emojis haha :)
I know you kid - but the _data_ in this context is the data that the app is processing at runtime. Ie. If the app is reading from a DB - that’s what we are tailing.
I wonder if we screwed up by calling out “tail” - it is so much more then that - it executes wasm rules on the client that are pushed to it by the server AND because we have access to the data - we can expose a UI to see it flowing… like a “tail -f” - but that doesn’t quite flow off the tongue :)
I’d urge you to check out the live demo and “tail” an app at runtime - it might be able to explain what we we are doing better than I can.
I don't actually have a problem for this to solve - like the rsync guy, I know how to use actual `tail -f` (and eg `perl -E` et al) - I'm just self-aware enough to realise that most people either aren't up to the task of hacking together whatever functionality they'd actually end up using out of generic utilities at all, or at least wouldn't consider that so easy as to be the path of least resistance to get something done.
And yep, you’re right - we are using protobuf to have a common schema between all SDKs, the server and UI.
Re: sdk implementation - it’s basically implementing grpc methods, knowing how to exec wasm and doing a couple of extra things at instantiation. In real terms - it took us about a week to implement the python SDK - that’s with learning how to do wasm, Protobuf and grpc in python + 1 week afterwards to iron out edge cases.
Re: Java - that was going to be the next sdk we do but we have no idea if it needs to be a specific Java version? Should we target lowest possible Java version? We need to have a solid wasm runtime support - so maybe that limits us to newer versions of Java. Is that a problem?
I did Java a looong time ago - so need some outside input at this point haha
Thanks for the info, sounds like you have a pretty solid tech stack :)
Re Java - If you're looking to maximise compatability, then yeah you should aim to target an older JDK. Virtually all Java projects use at least JDK 8 so that can be a baseline, however many enterprise projects would use closer to JDK 18 at a guess (Google's internally aiming to migrate to 21 in 2024). Generally if there are libraries or features from newer JDKs that you do want to use, I'd say just go for it, since JDK 11, the releases have been yearly (there was a three year gap between JDK 8 and 9) and more incremental.
What I would recommend is using Kotlin rather than Java, Kotlin's completely interoperable with Java, but provides a much nicer development experience. That way Kotlin clients get niceties such as named parameters [1] (which with data classes [2] can pretty well replicate StreamdalClient) [1] and Protobuf DSLs [3] and Java clients still get a first class, completely interoperable API.
No idea what WASM support is like for Java, I suspect it's lagging behind other implementations, however the most popular framework is Teavm.
> Re Java - If you're looking to maximise compatability, then yeah you should aim to target an older JDK. Virtually all Java projects use at least JDK 8 so that can be a baseline,
Oracle says that JDK 11 is on “Extended Support” which comes after “Premier Support”.[1] Why not just support JDK 17 and higher?
This is solid - thank you very much. We will do some more research but basically sounds like - go as low as possible, as long as the underlying libs support it.
And re: kotlin - I last worked/played with it in 2016 and recall that it was MUCH nicer to work in compared to Java.
I just did a quick cursory look and it seems like Kotlin only has slightly slower builds compared to Java and rest of perf is basically the same due to generating similar bytecode. Neat!
Good news then :) Everything stays on your network. Actually, in most situations - everything stays completely client-side. Because the rules that the client executes are Wasm modules, all data inspections and transformations occur in the client itself.
There is a server component (that you host) - but it is only used for pushing rules/Wasm down to the SDKs and for facilitating tail - that's it.
{kind=link}
I did not see any point to listing out the cons as others have already done it a bunch of times. I was trying to focus on what moving to a monorepo solved for us (which was optics and poor ux).